

Introduction
From the minute you start writing software, you start testing it. Good code goes to waste if it doesn't fulfill its intended purpose. Even a “hello, world” needs testing to make sure that it does its job. As your software grows in complexity and gets deeper, your testing must keep up. That's where test case management comes in. In this detailed guide, we'll dive into what test case management is, what it looks like in practice, and how to choose the right tool that makes things easier on the testing side.
What Is Test Case Management
Test case management is the practice of creating, organizing, and maintaining test cases throughout the software development lifecycle. It includes writing test cases based on software requirements, grouping them into test suites, executing them across different releases, and tracking results over time. To manage this effectively, teams also need a clear understanding of the difference between test plans and test cases and how each document fits into the overall testing process. This practice keeps all your testing organized in one place. Instead of hunting through different cases manually, your team can instantly see what needs to be checked and what's already been verified. As your product evolves, your testing dashboard stays updated and accessible to everyone who needs it.
What Is a Test Case Management System
A test case management system is a platform that facilitates your test management. It’s designed to create, execute, and monitor test cases in real-time, providing a centralized workspace for QA teams to prepare the software for deployment. Good test management platforms work alongside the tools your team uses every day. Using a test management system, teams can create, organize, assign, and execute large amounts of test cases with ease. And when something breaks during testing, you can flag it immediately without jumping between tools or re-typing details. At the end of the day, you can log in and out of this tool, and all your testing progress remains in the same place.
How Does Test Case Management Work
Rigorous testing translates into fully-functional software products. This is especially true if you have a layered product with extensive usability, which calls for creating and managing test cases without any hindrance. Here’s how it works in practice:
Define Requirements
Test case management begins with a thorough understanding of what you're building. During this phase, QA teams collaborate with product owners, developers, and stakeholders to gather functional specifications, user stories, acceptance criteria, and technical documentation. Think of this phase as a foundation to a multi-story building; you want to make it as strong as possible. Without clear requirements, testing becomes guesswork, which is never a good call.
Create Test Cases
Once requirements are clear, testers write structured test cases that explain exactly how to verify each feature. A solid test case includes:
- Preconditions (what needs to be ready first)
- Step-by-step instructions
- Expected results
- Any necessary test data
These cases should cover everything from “happy path” scenarios where users do everything right, as well as negative testing for error handling, edge cases with unexpected inputs, and boundary conditions at the limits. The goal is to build a library of clear, reusable test cases that any team member can execute consistently.
Organize Test Cases
As you create more test cases, your repository grows, which requires organization to prevent chaos. A test management tool enables you to group related test cases into logical test suites based on application modules, user workflows, sprint cycles, or risk levels. This organization makes it easy to locate specific tests when needed, run the right subset for different situations, and keep everything manageable as your product evolves and changes over time.
Pro Tip: TestFiesta also enables custom tagging, which means you can assign a custom tag to any test case so it’s easier to find it later without having to look up the case by its specific technical name or applying multiple filters.
Assign Test Cases
Once test cases are ready, the next step is to assign them to the right people. QA managers assign specific tests or test suites to team members based on their skills, availability, and workload. This might mean giving certain modules to testers who are well-versed in them, or spreading the workload evenly during busy release cycles. The point is: assigning test cases through a centralized platform makes it easier to collaborate with your team, track ownership, and monitor deadlines.
Execute Tests
Execution is where you perform actual tests. In this phase, testers follow the documented steps for each test case and compare actual results against expected outcomes. Manual execution involves hands-on interaction with the application, while automated tests run through scripts in CI/CD pipelines. During execution, testers can record pass/fail status, capture screenshots or logs for failures, and note any deviations from expected behavior.
Log Bugs & Issues
Test management systems have a really good workflow when it comes to test cases that fail. When a test fails, you can create detailed defect reports in issue tracking systems like Jira, GitHub, and others. These reports include environment details, severity ratings, supporting evidence (like screenshots or error logs), and, most importantly, how to reproduce the logged bug. Each bug report is linked back to the specific test case that found it, which creates clear traceability between passed and failed cases.
Track Progress
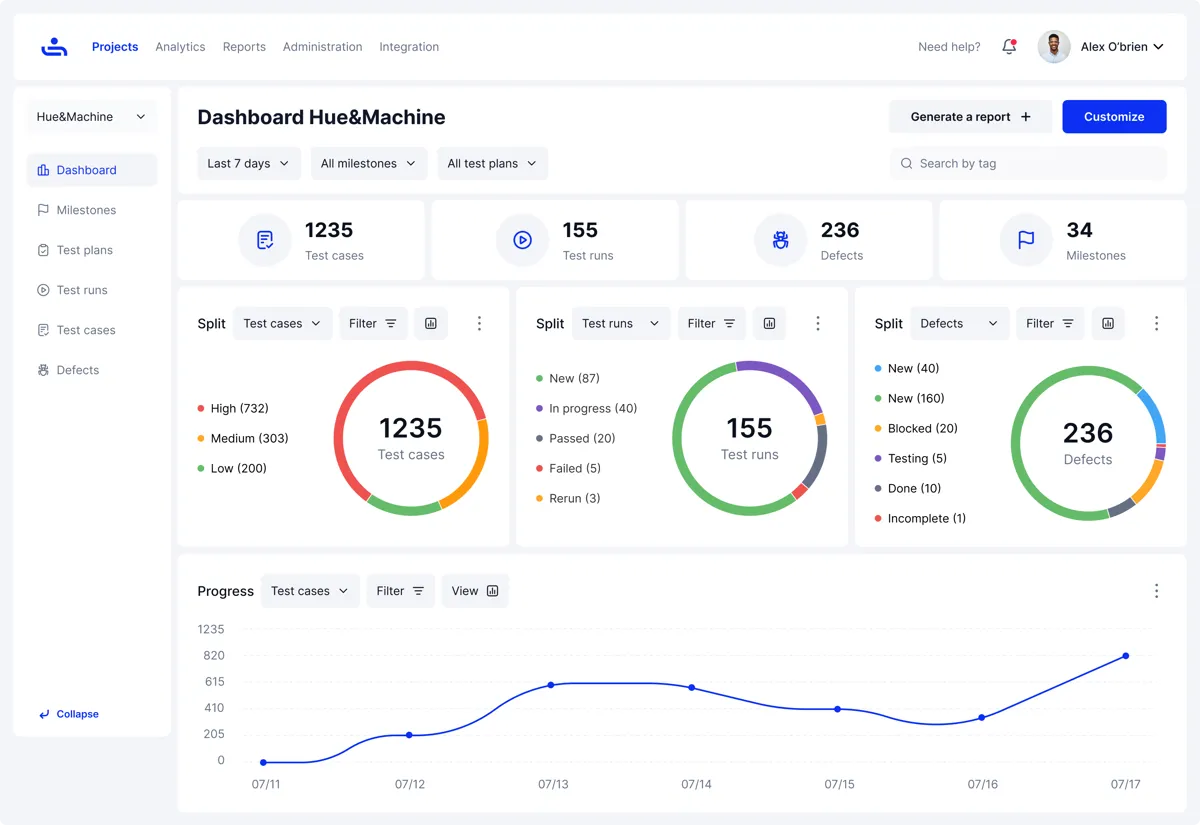
Clear visibility into your product’s testing status remains indispensable throughout the testing cycle. Some key metrics that you can monitor through a test management tool are test execution progress, pass/fail ratios, defect trends, coverage gaps, and testing speed. Dashboards and reports also reveal bottlenecks, highlight high-risk areas with many failures, and show how far the product is on track for release. When you have a clear picture, resource allocation becomes an easier decision.
Retest & Regression
After developers fix bugs, QA teams retest those specific scenarios to confirm the issues are actually resolved. But testing is like LEGO; fixing one thing can sometimes break another, which is where regression testing comes in. In regression testing, teams run broader test suites to make sure recent code changes haven't accidentally broken features that were working fine previously. This step keeps the usability of all features in check as your product gets ready for deployment.
Review & Optimize
Test cases aren't static documents; they require ongoing maintenance if you want them to support your evolving product. Regular reviews help identify outdated test cases that no longer match current functionality. When needed, teams can also perform optimizations, such as refining test case wording for clarity, updating test data, removing obsolete cases, and adding new ones for recent features.
Generate Reports
Your testing data plays a big part in your resource allocation and future planning. Test management systems generate comprehensive reports and dashboards that show test coverage, execution trends, defect distribution, release readiness scores, and quality metrics. These reports serve different audiences: managers use them to gauge sprint health, executives get a high-level view of product quality, and teams can establish their testing credibility during audits or compliance checks. Customizable reporting gets each stakeholder the information they need to make decisions.
Benefits of Using a Test Case Management Tool
A test case management tool transforms how QA teams work by bringing structure, visibility, and efficiency to the testing process. Below is a more detailed overview of the key benefits of using modern and flexible test management tools for your QA process.
Streamlines Test Execution and Tracking
A test case management app brings all testing activity into one place, removing the need to jump between multiple tools and Slack channels. Testers can run tests, log results, and keep an eye on the progress of the team; all without switching tabs. It cuts down on admin work and helps teams keep their testing flow steady.
Pro Tip: TestFiesta adds more flexibility to test management by simplifying your QA fiesta with custom fields and a user-friendly dashboard, getting the work done in far fewer clicks than most platforms.
Reduces Human Error and Redundancy
When test cases are centralized and version-controlled, duplicate work is out of the window. Teams are far less likely to counter inconsistencies in test processes because they follow the same standardized cases, which reduces manual errors and reinforces consistency across the workflow.
Improves Communication and Collaboration
A test case management app gives everyone access to the same testing data. Testers can check each other’s assignments, developers can see the tested features, QA leads can track progress, and stakeholders can review reports without needing manual updates from the team.
Speeds Up Releases Through Better Visibility
QA leads hate it when they don’t have a release date on the horizon, and it’s worse for marketing. A prominent benefit of a test management tool is clear visibility into testing status. Teams can identify blockers early and address them before release. As a result, everyone knows what's ready and what still needs attention—and release timelines become more predictable.
Supports Agile and Continuous Testing Workflows
Agile teams need quick adaptation, and a good test management platform fits the bill. It makes it easier to update test cases, rerun tests, and track results across sprints, keeping the workflow on track without hurdles.
How to Choose the Right Test Case Management System
Choosing the right test case management system depends on your team's size, workflow, and integration needs. Here's a step-by-step approach to evaluate and select the best tool:
Assess Your Testing Volume and Team Size
Start by understanding how many test cases your team manages on average and how many testers will use the system. You don’t need an exact number, but a ballpark helps you find the right match for your needs. Larger teams with extensive test suites need tools that can handle high volumes and provide strong access controls without breaking down. Smaller teams may prioritize simplicity and ease of use over advanced features.
Identify Required Integrations
Review the tools your team already uses, including issue trackers, like Jira and GitHub, and automation frameworks. An ideal test case management system should integrate with these tools to avoid creating workflow gaps. If you’re choosing a platform for a startup, look for mainstream features that help you ease into testing without many obstacles.
Check for Dashboard Analytics and Reporting Tools
Evaluate the reporting structure of a tool you want to use. The dashboard should display key metrics like test coverage, pass/fail rates, defect trends, and execution progress. A good tool should support flexible reporting that lets you customize views for different audiences, detailed metrics for QA leads, and high-level summaries for executives. The best tools make it easy to extract and share insights in multiple formats.
Compare Free vs. Paid Features
Many test case management tools offer free plans, which can be perfect for individual use or those trying things out. However, free tools often have limitations. Evaluate what's included and what's locked behind paywalls. Some tools limit essential features like integrations, custom workflows, advanced reporting, or user seats in their free versions. Review the feature breakdown carefully to determine whether a free plan genuinely meets your needs, or if upgrading is a valuable investment.
Try a Free Trial/Free Account Before Committing
Before making a decision, use your free trial to test the tool with real test cases and workflows. Create a project, write a few test cases, execute a test run, and evaluate how intuitive the interface is. A hands-on experience will give you an actual lookout into the tool’s functionality. If you get the hang of the platform easily, it might be time to bring in your team with an upgrade.
Using TestFiesta for Test Case Management
Testing isn’t supposed to be a daunting task. Unlike traditional test management tools that force teams into rigid, one-size-fits-all workflows, TestFiesta gives you the flexibility to build a workflow that fits your team's needs. With customizable fields, flexible tagging, and configurable test structures, teams can organize and execute tests in a way that makes the most sense for their projects.
TestFiesta supports integrations with Jira and GitHub, allowing testers to link defects directly to failed test cases. It also includes Fiestanaut AI, your personal copilot for AI-powered test case generation. You get shared steps for reusable test components and real-time collaboration tools that keep teams synchronized.
The best thing? TestFiesta offers a free plan for individual users with full feature access (no paywalls) and a flat-rate pricing model of $10 per user per month for organizations. No complex tires; just unwavering flexibility. Get started today.
Conclusion
Test case management turns scattered testing efforts into an organized, scalable process that grows with your product. When evaluating test case management tools, prioritize factors that directly impact your team's efficiency, including integrations, reporting, and pricing. The smartest approach is to pick a tool that allows flexible management of test cases while simultaneously fostering collaboration—without clunky, rigid interfaces. TestFiesta offers a free plan with complete feature access and straightforward $10/user/month team pricing. Build failsafe products with modular test management.
FAQs
What is test case management?
Test case management is the process of creating, organizing, and tracking test cases throughout the software testing lifecycle. QA teams get clearer visibility into test coverage, execution status, and defect tracking, harnessing releases with a more organized approach.
What is a test case management system?
A test case management system is software that facilitates test management. It helps teams create, execute, and monitor test cases in one centralized platform. A good system enables a smarter organization, simple execution, and efficient result tracking, without requiring you to switch tabs.
How is a free test case management system different from paid tools?
Free test case management systems typically offer basic functionality like test case creation, execution tracking, and simple reporting. Paid tools often include advanced features such as custom fields, automation integrations, detailed analytics, and priority support. TestFiesta provides full feature access in the free plan for individual users and charges a flat fee per user only for organizations.
What are the benefits of using a test case management app?
A test case management app streamlines test execution, reduces manual errors, and improves communication between QA, development, and stakeholders. A good test case management app provides better visibility into testing progress while supporting agile workflows. With a smart and flexible tool, teams can release software faster with higher quality.
How does a test case management dashboard help QA teams?
A test case management dashboard provides a real-time overview of testing activity, including test execution status, defect trends, and overall progress. It helps QA teams identify blockers, track completion, and make informed decisions about release readiness.
What is the price of a good test case management system?
TestFiesta offers a flat rate of $10 per user per month with no feature tiers or hidden costs. A free plan is also available for individual users.

