_%20Checklist%20%26%20Best%20Practices%20-%20Main%20Image.png)
Introduction
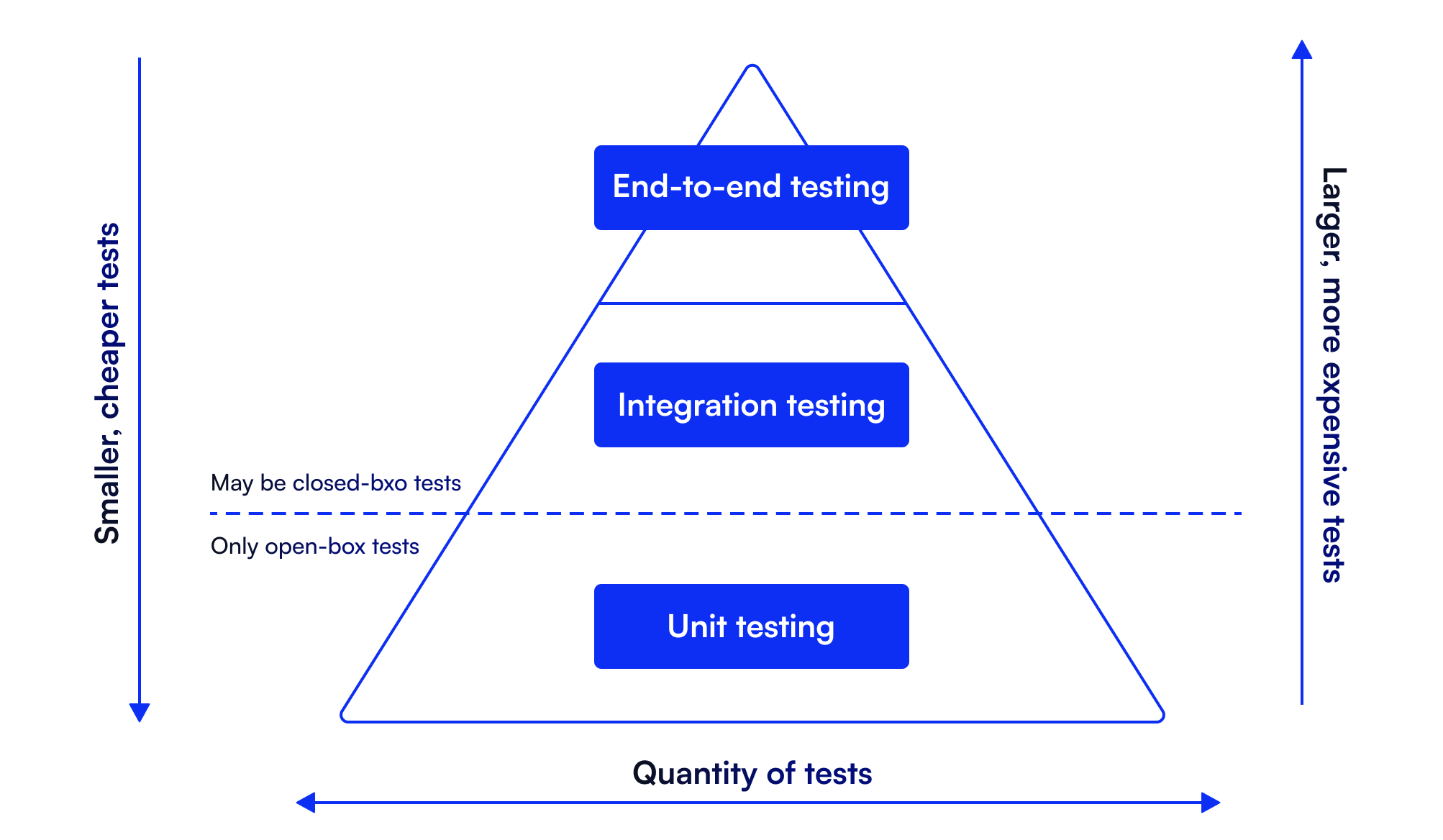
By the time software reaches user acceptance testing (UAT), it has already been through unit testing, integration testing, and probably a few rounds of QA. Technically, it should work. But “technically works” doesn’t translate to “actually ready” in a lot of cases. That’s the gap UAT exists to close.
User acceptance testing is the stage, the top of the testing pyramid, where real users and representatives get their hands on the software and decide whether it actually does what it’s supposed to do in the real world. Not in a test environment. Not against a list of technical requirements. In practice, with real workflows, real edge cases, and real expectations.
It’s the last line of defense before a product goes live. And when it’s done well, it catches the kind of issues that no automated test or QA checklist ever would, because those issues aren’t bugs in the traditional sense. They’re gaps between what was built and what was actually needed. This guide covers everything you need to run UAT properly, a practical checklist, best practices that actually hold up, and a clear breakdown of what to do at each stage of the process.
What Is User Acceptance Testing (UAT)?
User acceptance testing is the process of validating software against real-world business requirements before it’s released. It’s conducted by end users or business stakeholders, not the development or QA team, and the core question it’s trying to answer is simple: Does this software actually work for the people who are going to use it?
The purpose of UAT isn’t to find bugs in the technical sense. It’s to verify that the software behaves the way the business intended and that users can complete their tasks without friction or missing functionality. A system can pass every technical test and still fail UAT, because the people who built it and the people who use it often have very different definitions of “working correctly.”
How UAT Differs from Traditional Testing
Most testing before UAT is done by people who built the software or are exclusively paid to break and test it.
QA or software testing checks whether the application behaves according to its technical specifications.
UAT is different because it’s about reality. It puts the software in front of the people who will actually use it and asks whether it fits into their world.
Importance of User Acceptance Testing (UAT) in Software Testing
No matter how thorough your internal testing is, it’s always happening at a distance from the people the software is actually built for. UAT closes that distance. It brings real users into the process at the most critical moment, right before release, and allows them to flag issues that technical testing simply isn’t designed to catch.
UAT is particularly crucial when you get into the actual cost of finding and fixing bugs. The cost of finding a problem after launch is significantly higher than finding it before, both in terms of time and the impact it has on user trust. UAT is a final checkpoint before launch.
Beyond bug catching, UAT also serves as an alignment check between what the business asked for and what was actually delivered, which, unfortunately, aren’t always the same thing, even on well-managed projects. If UAT is done consistently, it leads to fewer post-release surprises, smoother rollouts, and software that people can actually use without needing a manual.
Types of User Acceptance Testing
UAT isn’t a one-size-fits-all process. Depending on the nature of the software, the industry, and where it is in its release cycle, different types of acceptance testing serve different purposes. Here’s a breakdown of the most common ones.
Alpha Testing
Alpha testing is the earliest form of UAT. It’s done in a controlled environment, usually in-house by a select group of internal users or stakeholders, before the software is opened up to anyone outside the organization. The goal is to catch usability issues, workflow gaps, and requirement mismatches early, while there’s still plenty of time to make changes. It’s not as polished as later testing stages, and that’s intentional; the rougher edges tend to surface the most useful feedback.
Beta Testing
Beta testing comes after alpha and involves releasing the software to a limited group of real external users before the full public launch. These users interact with the product in their own environment, on their own terms, which surfaces the kind of real-world issues that a controlled test setting never could. You might have noticed new apps or new updates in apps often labeled as “beta,” which means you are an opt-in beta tester. Feedback from beta testing is invaluable, not just for catching bugs, but for understanding how people actually use the product versus how it was designed to be used.
Alpha testing and beta testing are often grouped together for the best results.
Contract Acceptance Testing
Contract acceptance testing is used when software is being built to fulfill a specific contract or set of agreed-upon requirements. Before the client accepts delivery, the software is tested against every condition outlined in the contract to verify that everything has been delivered as promised. If something doesn’t meet the agreed standard, it goes back for fixes before sign-off. It’s a more formal process and often involves both the vendor and the client working through a defined checklist together.
Regulation Acceptance Testing (Compliance Testing)
Some industries operate under strict regulatory requirements. Healthcare, finance, and legal are the most obvious examples where enterprise software testing is compliance-driven. Regulation acceptance testing verifies that the software meets all applicable legal and compliance standards before it goes live. Skipping this or treating it as an afterthought isn’t just a quality risk; in regulated industries, it can be a legal one. This type of testing is usually conducted with input from compliance teams or external auditors who understand the specific regulations the software needs to adhere to.
Tools to Use In User Acceptance Testing
Running UAT without the right tools in place is a quick way to end up with scattered feedback, missed issues, and no clear record of what was tested. The right toolset keeps everything organized and gives everyone involved a shared view of where things stand.
Test Management System
A test management system is where your UAT process lives. It’s where test cases are written, assigned, and executed, and where results are recorded. Having everything in one place means nothing gets lost in spreadsheets or email threads, and stakeholders can check progress at any point without having to chase anyone for an update.
Issue Tracker
When testers find problems during UAT, those issues need to go somewhere actionable. An issue tracker captures bugs and feedback in a structured way, assigns them to the right people, and tracks them through to resolution. Without one, issues get reported in inconsistent formats, fall through the cracks, or get fixed without any record of what changed.
User Feedback Gathering Tools
UAT goes beyond validating structured test cases; it’s about seeing the product through the user’s eyes. Tools like surveys, feedback forms, and session recordings surface the kind of qualitative insights that a simple pass/fail outcome misses.
Many of the most valuable findings at this stage aren’t bugs. They’re friction points: unclear workflows, confusing interactions, or features that technically work but don’t feel intuitive in practice. Creating a clear, dedicated channel for this kind of feedback ensures these insights are captured, understood, and acted on, rather than getting overlooked.
Benefits of Having a UAT Checklist
A well-defined UAT checklist brings structure to what can otherwise become a scattered and inconsistent process. It helps teams stay aligned, ensures critical scenarios are covered, and makes the entire validation phase more reliable.
Here’s how a UAT checklist adds value:
- Ensures complete coverage: Key user flows and business-critical scenarios are less likely to be missed when everything is clearly outlined.
- Keeps testing consistent: Different testers follow the same criteria, which reduces variability in how the product is evaluated.
- Speeds up the testing process: Testers spend less time figuring out what to validate and more time actually testing.
- Reduces the risk of last-minute surprises: Catching gaps early prevents critical issues from surfacing right before release.
- Makes sign-off more confident: Stakeholders can approve releases knowing that all agreed-upon scenarios have been validated.
- Creates a reusable framework: The same checklist can be refined and reused across future releases, saving time and improving quality over time.
In practice, a UAT checklist acts as both a guide and a safety net, keeping testing focused while ensuring nothing important slips through the cracks.
User Acceptance Testing (UAT) Checklist
A UAT process without a checklist is easy to rush through or cut short, especially when release deadlines are close. This checklist walks through everything that needs to happen before, during, and after UAT to make sure nothing important gets skipped.
Define UAT Scope
Before anything else, get clear on what’s actually being tested. Not every feature or workflow needs to go through UAT every cycle.
Define which requirements, user stories, or business processes if you are working with a defined scope, and make sure everyone involved agrees on that list before testing begins.
Set Up the UAT Environment
UAT should happen in an environment that mirrors production as closely as possible. That means real data, real configurations, and real system integrations, not a stripped-down test environment that behaves differently from what users will actually encounter. Any gaps between the UAT environment and production are gaps where issues can hide.
Create UAT Plan
The UAT plan is the document that holds everything together. It should cover the testing objectives, timeline, roles and responsibilities, entry and exit criteria, and how feedback will be collected and handled. Having this in place before testing starts means everyone knows what they’re doing and why.
Select Testers
The testers in UAT should be the people who actually understand the business requirements, end users, business analysts, or key stakeholders. Avoid the temptation to use internal QA team members as a substitute. The whole point of UAT is to get feedback from people who represent the real user, and that only works if the right people are in the product.
Develop Test Cases
UAT test cases should be written around real business scenarios and user workflows, not technical specifications. Each test case should reflect something a user would actually need to do in practice. Keep them clear and straightforward so that non-technical testers can execute them without needing guidance at every step.
Choose a Test Management Tool
UAT can’t be managed through spreadsheets or email threads. You’ll lose track of results, feedback, and issue status. A good test management tool keeps everything in one place: test cases, execution status, defects, and sign-off, so nothing slips through and stakeholders always have a clear view of where things stand.
Review and Approve
Before testing begins, have the UAT plan, test cases, and environment reviewed and signed off by the relevant stakeholders. This step exists to catch gaps before they become problems mid-testing. It also ensures everyone is aligned on what success looks like before the process starts.
Execute Test
This is where testers work through the defined test cases and document their results. Every pass, fail, and observation should be recorded, not just the issues. A clear record of what was tested and what the outcome was is essential for the sign-off conversation that comes later.
Gather Feedback
Beyond structured test case results, give testers a way to share general observations about their experience. Some of the most valuable UAT input comes outside of the formal test cases, a workflow that feels unnecessarily complicated, a confusing label, or a step that’s missing entirely. Make it easy for testers to capture that kind of feedback as they go.
Validate Test Cases
Once testing is complete, go back through the results and validate that everything was executed correctly and that the outcomes are accurate. Check that failed test cases have corresponding defects logged, that edge cases were covered, and that nothing in scope was skipped.
Review and Refine the UAT Process
After each UAT cycle, take some time to look at how the process itself performed. Were the test cases well written? Did the environment cause any unnecessary issues? Was feedback collected effectively? UAT gets better with iteration, and the teams that treat each cycle as a learning opportunity end up with a significantly smoother process over time.
Common Challenges Faced in UAT
UAT is one of the most important stages of the software testing life cycle, and one of the most commonly mishandled. These are the challenges that come up most often and what you can do about them.
Not Enough Internal QA
When UAT is under-resourced, when you don’t have enough testers, time, or the right people, it becomes a surface-level exercise that misses the issues it was designed to catch. The fix is treating UAT as a planned activity, not an afterthought. Allocate time for it properly, involve the right stakeholders early, and make sure testers have the bandwidth to actually do the work.
Poor Test Planning
Jumping into UAT without a solid test plan leads to inconsistent results and no clear path to sign off. Define the scope, write clear test cases, and agree on entry and exit criteria before testing begins. It doesn’t have to be complicated; it just has to happen before testing starts.
Following Traditional "Rules" of Testing
Applying a QA mindset to UAT is a common mistake. UAT testers should be thinking like users, not like testers, working through real workflows, questioning whether things make sense, and flagging anything that feels off, even if it technically passes.
Using the Wrong Testing Environment
If the UAT environment doesn’t reflect production accurately, the results won’t be reliable. Missing integrations, different configurations, or unrealistic test data will cause real issues to go undetected until after release. Mirror production as closely as possible before testing begins.
Not Using the Right Test Management Tool
Managing UAT through spreadsheets and email threads falls apart quickly once testing is underway. A proper test management tool keeps test cases, results, defects, and sign-off status in one place, giving everyone a clear, shared view of where things stand throughout the process.
Best Practices for Performing User Acceptance Testing
How you run UAT matters just as much as whether you run it. These best practices won’t just make the process smoother; they’ll make the results more reliable and the eventual release more confident.
Involve Stakeholders Early
Don’t bring stakeholders in at the execution stage and expect meaningful feedback. The earlier they’re involved in defining scope, reviewing test cases, and setting expectations, the more useful their input will be. Stakeholders who understand the process from the start are also much easier to get sign-off from at the end.
Develop Clear and Detailed UAT Criteria
Vague acceptance criteria lead to vague results. Before testing begins, define exactly what a pass looks like for each test case and what conditions need to be met before the software can be signed off. When the criteria are clear, there’s no room for disagreement about whether UAT has been completed successfully.
Simulate Real-World Conditions
UAT should reflect the environment and conditions users will actually encounter, real data, real workflows, and real system integrations. The closer the testing conditions are to production, the more reliable the results. Anything less and you risk signing off on software that works in testing but breaks in the real world.
Prioritize Test Cases
Not all test cases carry the same weight. Focus testing effort on the workflows and requirements that matter most to the business first. If time runs short, and it often does, you want to be confident that the critical paths have been thoroughly tested, even if some lower priority cases didn’t get covered.
Maintain Transparent Communication
UAT involves a lot of moving parts and a lot of different people. Keeping communication open and consistent between testers, developers, and stakeholders prevents misunderstandings, speeds up issue resolution, and keeps everyone aligned on where things stand. Issues that get communicated clearly get fixed faster.
Use a Reliable Test Management Tool
A reliable test management tool is what keeps UAT from becoming chaotic. It gives the team a single place to manage test cases, track execution, log defects, and document sign-off, so nothing gets lost and stakeholders always have visibility into progress.
User Acceptance Testing With TestFiesta
UAT works best when everything is in one place, and that’s exactly what TestFiesta is built for. Instead of managing test cases in spreadsheets, logging bugs in a separate tool, and chasing stakeholders for feedback over email, TestFiesta brings the entire UAT process into a single platform.
Teams can build out UAT plans, write test cases around real business scenarios, assign them to the right testers, track defects, and see execution progress in real time, all without switching tools. Stakeholders can check in at any point and see exactly where things stand without needing a status update.
When testers find issues during UAT, they can log them directly in TestFiesta, automatically linked to the exact test case that found them. For teams using Jira, those bugs sync natively, so developers are always working from the same information.
With test results, defect status, and execution history all in one place, the sign-off process becomes significantly less stressful; everything stakeholders need to make a release decision is already documented and easy to find.
Conclusion
UAT is the final checkpoint between your software and the people who are going to use it. Getting it right means involving the right people, planning properly, testing in realistic conditions, and having the tools in place to keep everything organized.
The teams that treat UAT as a genuine validation exercise, rather than a formality at the end of the development cycle, are the ones that ship with confidence and deal with fewer surprises after release. The checklist and best practices in this guide give you a solid foundation to build that kind of process, regardless of where your team is starting from.
FAQs
What is the purpose of test runs and milestones in UAT?
Test runs give teams a structured way to execute and record UAT results in an organized cycle. Milestones mark key points in the process, like when testing begins, when a certain percentage of test cases have been executed, or when sign-off is achieved. Together, they keep UAT on track and give stakeholders clear checkpoints to reference throughout the process.
Should user acceptance testing follow documented requirements?
Yes. UAT test cases should be built around documented business requirements and user stories. Without that foundation, there's no reliable way to determine whether the software actually meets what was asked for. Undocumented requirements lead to subjective feedback that’s hard to act on.
What is the UAT environment, and how should the UAT test environment be prepared?
The UAT environment is the setup in which acceptance testing takes place. It should mirror production as closely as possible, with the same configurations, real or realistic data, and all system integrations in place. Any gaps between the UAT environment and production are gaps where real issues can go undetected until after release.
What is the best way to prioritize bugs during UAT?
Focus first on bugs that affect critical business workflows or block testers from completing test cases. After that, prioritize by severity and the frequency with which a user would encounter the issue. Cosmetic or low-impact bugs can be addressed after the core functionality has been validated.
How is UAT different from system testing?
System testing is conducted by the QA team to verify that the software meets its technical specifications. UAT is conducted by end users or business stakeholders to verify that the software meets real-world business requirements. System testing checks whether it works correctly. UAT checks whether it works for the people using it.
Who should perform UAT?
UAT should be performed by end users, business stakeholders, or people who closely represent the target user. The key is that testers should understand the business requirements and workflows, not just the technical side of the software. Internal QA team members are not a substitute for real user involvement in UAT.
What is a UAT tester?
A UAT tester is someone who validates software from a business or end-user perspective. Unlike QA testers, they aren’t looking for technical bugs; they’re evaluating whether the software works the way the business intended and whether real users can complete their tasks without unnecessary friction or confusion.
When should UAT be performed?
UAT should be performed after development and internal QA testing are complete, and before the software is released to production. It’s the final validation stage, the last opportunity to catch issues before real users encounter them.
Can UAT be automated?
Partially. Some structured test cases with predictable, repeatable outcomes can be automated. However, a significant part of UAT involves human judgment, evaluating usability, assessing whether workflows make sense, and capturing qualitative feedback. That side of UAT can’t be fully automated, which is why real user involvement remains essential.
What are test scenarios in UAT?
Test scenarios in UAT are high-level descriptions of real business situations that the software needs to handle. They form the basis for writing individual test cases. For example, a test scenario might be “a user completes a purchase from product selection to order confirmation”, and the test cases underneath it would walk through each step of that process in detail.
What does planning look like for UAT?
UAT planning involves defining the scope of testing, identifying and onboarding testers, setting up the testing environment, writing test cases, establishing entry and exit criteria, and agreeing on a timeline. A UAT plan document that captures all of this gives everyone involved a shared reference point and prevents the process from becoming disorganized once testing begins.
Is UAT necessary for small updates?
It depends on what the update touches. Small cosmetic changes or minor bug fixes may not require a full UAT cycle. But any update that affects a core business workflow, user-facing functionality, or system integration is worth validating with real users, even if the scope of testing is reduced. The size of the update doesn’t always reflect the size of the potential impact.
How do you analyze UAT results effectively?
Start by reviewing all test case outcomes and categorizing defects by severity and business impact. Look for patterns; if multiple testers struggled with the same workflow, that’s a signal worth taking seriously. Compare results against the entry and exit criteria defined in the UAT plan, and make sure every failed test case has a corresponding defect logged before moving toward sign-off.
When does UAT happen in the SDLC?
UAT happens near the end of the software development lifecycle, after development, unit testing, integration testing, and QA testing have all been completed. It’s the final validation stage before a product moves into production.
Is UAT different from QA testing?
Yes. QA testing is conducted by a dedicated testing team that evaluates the software against technical specifications. UAT is conducted by end users or business stakeholders who evaluate the software against real-world business requirements. QA testing checks whether the software works correctly. UAT checks whether it works for the people it was built for.
What are common types of UAT?
The most common types of UAT include alpha testing, beta testing, contract acceptance testing, and regulation acceptance testing, all of which are covered in detail earlier in this guide. Other types include operational acceptance testing, which validates that the software is ready to be supported and maintained in a live environment, and black box testing, where testers evaluate the software purely from a user perspective without any knowledge of the underlying code or architecture. Smoke testing is another form of acceptance testing, but it’s build-acceptance testing that happens at the start of the development process instead of the end.
How do you make UAT feedback actionable for developers?
Vague feedback is hard to act on. Encourage users to be as specific as possible about what they were trying to do, what happened, and what they expected to happen instead. Every piece of feedback should be logged with enough context for a developer to understand and reproduce the issue. A test management tool helps here by giving testers a structured way to capture and submit feedback rather than relying on informal channels.
What are the next steps after UAT?
Once UAT is complete and the exit criteria have been met, the software moves toward release. Any outstanding defects should be triaged and either resolved before launch or documented as known issues with a resolution plan. A formal sign-off from stakeholders should be obtained before the release goes ahead, and a post-release review should be scheduled to evaluate how UAT performed and what can be improved next time.
How does TestFiesta support user acceptance testing (UAT)?
TestFiesta brings the entire UAT process into one platform through flexible test management features. Teams can write and organize test cases, track execution progress in real time, log bugs directly linked to the test cases that found them, and manage stakeholder sign-off, all without switching tools. For teams using Jira, bugs sync across natively so developers always have the full picture. It removes the operational overhead that usually makes UAT harder than it needs to be.

_%20All%20Stages%20Explained%20-%20Thumbnail%20Image.png)

_%20A%20Guide%20for%20Testers%20-%20Main%20Image.png)